Ricoh/Fujitsu ScanSnap-Support
Durchsuchbare PDF-Dokumente erstellen
Was sind durchsuche PDFs und warum dauert das so lange?
Eine gescannte Papiervorlage ergibt erst einmal nur ein grafisches Abbild, welches vom ScanSnap als JPeg-Datei gespeichert oder als Grafik in ein PDF-Dokument eingebunden wird. Das, was wir als Text in diesem Bild erkennen, ist für den Computer nur eine Ansammlung von Bildpunkten. Hier kommt eine OCR-Texterkennungssoftware zum Einsatz, die in den Pixelmustern die einzelnen Zeichen erkennt, mit Hilfe eines Wörterbuches Texte generiert und diese zusammen mit dem gescannten Bild in die PDF-Datei schreibt. Der Text wird dabei in den Hintergrund gelegt und ist nicht sichtbar, wenn Sie das PDF-Dokument öffnen. Desktop-Suchprogramme und Dokumenten-Management-Systeme können diesen aber in ihren Index schreiben und dem Anwender eine datenbankgestützte Volltextrecherche ermöglichen. Daher der Begriff "durchsuchbare PDF". Die Erkennung des Textes durch ein OCR-Programm erfordert viel Prozessorleistung und ist dadurch zeitaufwändig.
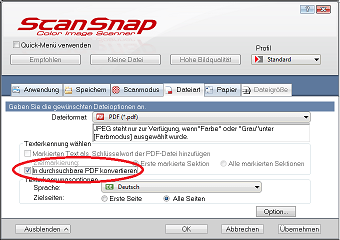
Im ScanSnap Manager können Sie einstellen, ob OCR ausgeführt werden soll und wenn ja, ob nur für die erste oder für alle Seiten. Öffnen Sie dazu bitte die Seite Dateiart und markieren Sie In durchsuchbare PDF konvertieren, um OCR einzuschalten. Bei Zielseiten wird i. d. R. Alle Seiten gewählt, um eine Suche im gesamten Dokument zu ermöglichen. Die Erkennungssprache kann hier leider nur fest vorgegeben werden.
Wenn Sie Papierdokumente mit häufig wechselnden Sprachen scannen, dann können Sie alternativ den mitgelieferten "ABBYY FineReader for ScanSnap" verwenden: Deaktivieren Sie dazu die Option In durchsuchbare PDF konvertieren und wählen Sie auf der Seite Anwendung bitte "ABBYY Scan to Searchable PDF". Beenden Sie den ScanSnap Manager mit OK. Starten Sie das Programm "ABBYY FineReader for ScanSnap" über das Windows-Startmenü, um wichtige Einstellungen vorzunehmen. Auf der Seite Allgemeine Optionen können Sie mehrere Sprachen markieren, das Programm erkennt dann selbst, in welcher Sprache bzw. welchen Sprachen das zu archivierende Dokument geschrieben wurde. Wichtig für die Archivierung ist hier noch die Einstellung Speichermodus auf Seite Scan to Searchable PDF: hier muss "Text unter dem Seitenbild" gewählt werden, damit das gescannte Dokumentenabbild erhalten bleibt.
Tipp
Anwendende der Archivierungslösung "Office Manager DMS" können die nachträgliche OCR-Ausführung aktivieren und ohne Zeitverlust weiterarbeiten, während die Texterkennung im Hintergrund ausgeführt wird.